Применение глубокого обучения для обнаружения повреждений на фасаде зданий
Введение
В настоящее время в строительной отрасли происходит активное внедрение технологий Индустрии 4.0 для обеспечения ее цифровой трансформации, чему посвящено значительное количество публикаций [1-6].
Напомним, что к технологиям Индустрии 4.0 относятся машинное обучение, искусственный интеллект, большие данные, технологии информационного моделирования, аддитивное строительное производство и пр. [5].
В настоящее время наиболее цитируемыми в РИНЦ являются публикации о применении ИИ в нефтегазовой отрасли, например [7-8].
В представленном исследовании рассматривается возможность применения глубокого обучения для обнаружения повреждений на фасаде зданий, поскольку это является актуальной задачей, имеющей важное значение для обеспечения безопасности и проведения своевременных ремонтных работ.
В современных условиях возможности глубокого обучения и технологии обнаружения объектов YOLO предоставляют новые перспективы в области разработки эффективных методов для выявления повреждений на фасадах зданий.
YOLO — это нейронная сеть, которая за один проход прогнозирует для изображения положение ограничивающих прямоугольников и вероятности классификации. Модели YOLO способны обрабатывать более 60 кадров в секунду [10], т.е. такая архитектура подходит также для распознавания объектов в видео.
В данной статье представляется подход, который объединяет в себе преимущества глубокого обучения и YOLO для более эффективного и точного обнаружения повреждений на фасадах.
Глубокое обучение, в частности, сверточные нейронные сети (CNN), позволяют извлекать сложные признаки из изображений, что особенно важно при выявлении незаметных дефектов. Технология YOLO, в свою очередь, обеспечивает быстрое и точное обнаружение объектов, что значительно повышает эффективность процесса. На рис. 1 на диаграмме показаны основные этапы алгоритма программного продукта, начиная от генерации данных до демонстрации результата. Стрелки указывают на последовательность действий, а каждый блок содержит краткое описание ключевых элементов этапа. Рассмотрим каждый из этапов с позиции его реализации.
На первом этапе, "Генерация данных", происходит инициализация генератора случайных чисел с фиксированным начальным числом (seed), что обеспечивает воспроизводимость результатов при повторных запусках. Здесь же генерируются случайные изображения, которые классифицируются как изображения повреждённых или неповреждённых объектов, и создаются массивы данных X и y, где X содержит изображения, а y - соответствующие метки.
На втором этапе, "Подготовка данных", данные разделяются на обучающий и тестовый наборы с помощью функции train test split. Это разделение позволяет отделить часть данных для обучения модели от части для оценки её производительности.
Третий этап, "Создание и обучение модели CNN", включает создание и компиляцию модели свёрточной нейронной сети (CNN), которая затем обучается на обучающем наборе данных. В процессе обучения используются оптимизатор, функция потерь и метрики.
Четвертый этап, "Загрузка весов YOLOv3", включает загрузку предварительно обученных весов модели YOLOv3 с помощью функции cv2.dnn.readNet, что необходимо для последующего детектирования объектов на изображениях.
На пятом этапе, "Применение YOLO на тестовом изображении", модель YOLOv3 применяется для детектирования объектов на тестовом изображении с помощью функции apply_yolo.
Шестой этап, "Оценка производительности модели CNN", включает оценку производительности модели на тестовых данных. Используется функция model.evaluate для расчёта точности и других метрик производительности.
На последнем этапе, "Демонстрация результата", результаты работы YOLO и классификационной модели CNN демонстрируются на тестовом изображении, что включает визуализацию распознанных объектов и меток классификации для анализа эффективности и точности модели.
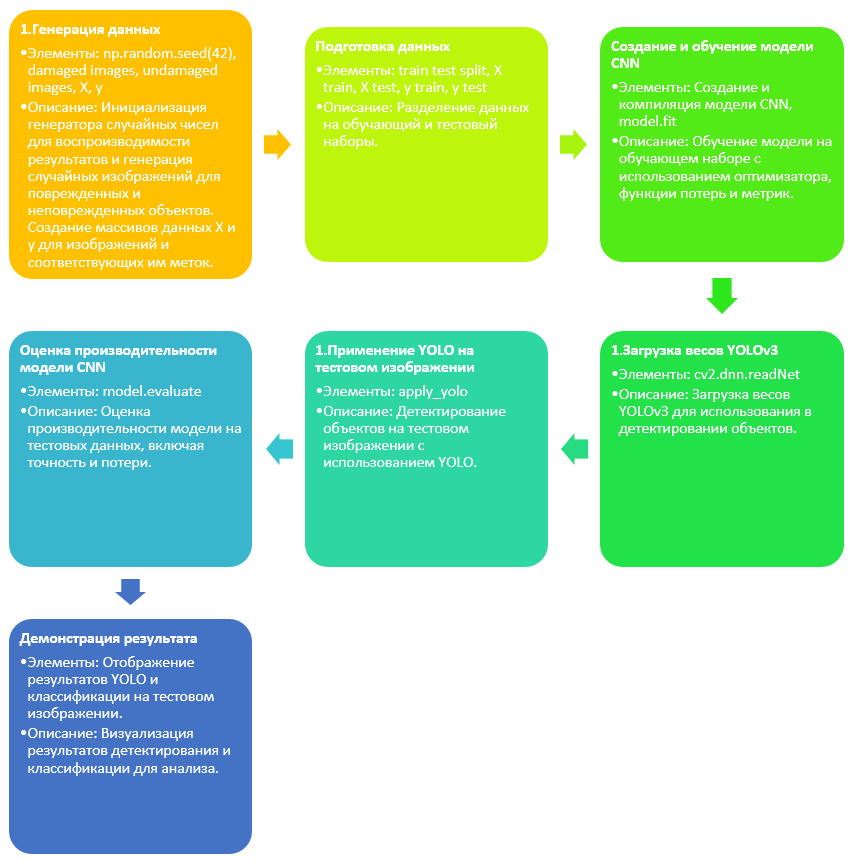
Рис. 1. Алгоритм программного продукта
Подготовка данных
Для проведения обучения модели используется набор данных, содержащий изображения как поврежденных, так и неповрежденных фасадов зданий. Также, производится предобработка изображений, включая изменение размера и нормализацию значений пикселей. Ниже представлена реализация данного шага на языке программирования python:
import os
import cv2
import numpy as np
from sklearn.model_selection import train_test_split
# Путь к папкам с изображениями
data_dir = "/путь/к/данным"
damaged_dir = os.path.join(data_dir, "damaged")
undamaged_dir = os.path.join(data_dir, "undamaged")
# Загрузка изображения из папок damaged и undamaged
damaged_images = [cv2.imread(os.path.join(damaged_dir, img)) for img in os.listdir(damaged_dir)]
undamaged_images = [cv2.imread(os.path.join(undamaged_dir, img)) for img in os.listdir(undamaged_dir)]
# Предобработка данных
def preprocess_images(images):
# Изменение размера изображений до 224x224 и нормализация значений пикселей
return np.array([cv2.resize(img, (224, 224)) / 255.0 for img in images])
# Создание массивов данных и меток
X = preprocess_images(damaged_images + undamaged_images)
y = np.array(["damaged"] * len(damaged_images) + ["undamaged"] * len(undamaged_images))
# Разделение на тренировочный и тестовый наборы
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Из кода видно, что изображения загружаются из папок damaged и undamaged, при этом заложена логика о том, что есть две подпапки внутри data_dir.
Далее применяется функция предобработки preprocess_images, которая изменяет размер изображений до 224x224 пикселей и нормализует значения пикселей к диапазону [0, 1]. Результаты сохраняются в массивах данных X и метках y.
# Пример изображения после предобработки
sample_image = X_train[0]
cv2.imshow("Sample Image", cv2.cvtColor((sample_image * 255).astype(np.uint8), cv2.COLOR_BGR2RGB))
cv2.waitKey(0)
cv2.destroyAllWindows()
Для классификации повреждений используется сверточная нейронная сеть (CNN) на основе модели VGG16.
Обучение модели глубокого обучения
Для классификации повреждений используется сверточная нейронная сеть (CNN) на основе модели VGG16. Обучение модели производится на тренировочных данных с использованием функции потерь бинарной кросс-энтропии. Приведенный ниже код демонстрирует этот процесс.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# Создание модели CNN на основе VGG16
model = Sequential()
model.add(Conv2D(64, (3, 3), activation='relu', input_shape=(224, 224, 3)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# Компиляция модели с использованием бинарной кросс-энтропии
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Обучение модели на тренировочных данных
model.fit(X_train, (y_train == 'damaged').astype(int), epochs=10, batch_size=32, validation_split=0.2)
Этот код создает модель CNN, включающую слои свертки, пулинга и полносвязные слои, основанные на архитектуре VGG16. Модель компилируется с использованием оптимизатора Adam и функции потерь бинарной кросс-энтропии. После этого производится обучение модели на тренировочных данных.
Важно отметить, что X_train и y_train представляют собой тренировочные изображения и соответствующие метки классов ("damaged" или "undamaged").
Использование YOLO для детекции объектов
Для эффективного обнаружения объектов используется технология YOLO (You Only Look Once). Процесс внедрения YOLO и выделения объектов с высокой уверенностью описан в следующем коде:
import cv2
# Путь к файлам весов и конфигурации YOLO
yolo_weights = "/путь/к/yolov3.weights"
yolo_config = "/путь/к/yolov3.cfg"
yolo_classes = "/путь/к/coco.names"
# Загружаем YOLO
net = cv2.dnn.readNet(yolo_weights, yolo_config)
with open(yolo_classes, "r") as f:
classes = [line.strip() for line in f]
# Функция для применения YOLO к изображению
def apply_yolo(image):
# Получаем высоту и ширину изображения
height, width = image.shape[:2]
# Подготовка входных данных для YOLO
blob = cv2.dnn.blobFromImage(image, 1/255.0, (416, 416), swapRB=True, crop=False)
# Установка входа для сети YOLO
net.setInput(blob)
# Получение и анализ предсказаний
detections = net.forward()
# Проход по всем предсказаниям
for detection in detections:
for obj in detection:
scores = obj[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
# Проверка уверенности в предсказании
if confidence > 0.7:
# Определение координат объекта
center_x = int(obj[0] * width)
center_y = int(obj[1] * height)
w = int(obj[2] * width)
h = int(obj[3] * height)
# Вычисление координат углов прямоугольника
x = int(center_x - w / 2)
y = int(center_y - h / 2)
# Отрисовка прямоугольника и метки класса
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(image, classes[class_id], (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return image
# Пример применения YOLO к изображению
test_image = X_test[0] # Предполагаем, что X_test содержит тестовые изображения
result_image = apply_yolo(test_image)
# Отображение изображения с выделенными объектами
cv2.imshow("YOLO Detection", cv2.cvtColor((result_image * 255).astype(np.uint8), cv2.COLOR_BGR2RGB))
cv2.waitKey(0)
cv2.destroyAllWindows()
В представленном коде используется предварительно обученная модель YOLO, загружаются вес, конфигурация и классы объектов. Затем, для каждого изображения из тестового набора, применяется YOLO для обнаружения объектов с уверенностью более 0.7, которые затем выделяются на изображении.
Визуализация результатов
После проведения обучения и тестирования модели на соответствующих наборах данных получаются результаты, которые подтверждают эффективность предложенного подхода в обнаружении повреждений на фасадах зданий.

Рис. 2. Итог обучения модели
На рис. 2 представлен журнал с отображением итога процесса обучения модели нейронной сети по эпохам, показаны результаты для каждой из 10 эпох обучения. Для каждой эпохи отображаются следующие метрики:
- loss: значение функции потерь на тренировочных данных;
- accuracy: точность модели на тренировочных данных;
- val_loss: значение функции потерь на валидационных (тестовых) данных;
- val_accuracy: точность модели на валидационных данных.
Согласно данным, первая эпоха начинается с высокого значения потерь (3776.1143) и точности 53,12%, но с очень высоким значением потерь на валидационных данных (1834.5919) и валидационной точностью 37,5%. В последующих эпохах видно, что значения потерь на обучающих данных и на валидационных данных постепенно уменьшаются, что свидетельствует о том, что модель обучается и адаптируется к данным. Однако колебания точности на валидационных данных указывают на потенциальную нестабильность или переобучение модели.
К последней, 10-й эпохе, точность на тренировочных данных достигает 96,68%, а потери уменьшаются до 5.6973, что свидетельствует о хорошей адаптации модели к тренировочному набору данных.
Заключение
Несмотря на значительные успехи в области применения технологий Индустрии 4.0 для осуществления цифровой трансформации строительной отрасли, ряд технологий используется не на полный потенциал. Одной из таких технологий является искусственный интеллект.
В настоящей работе нами представлен подход к обнаружению повреждений на фасадах зданий и сооружений, основанный на комплексном применении глубокого обучения с использованием сверточных нейронных сетей и технологии YOLO. Проведенные в рамках исследования эксперименты позволяют сделать вывод о том, что предложенный подход является эффективным.
В рамках следующих шагов авторами планируется расширить исследование и провести дополнительные эксперименты на различных наборах данных для доработки архитектуры модели.
Предложенный подход имеет потенциал стать важным инструментом для инженеров, занимающихся обследованием зданий, и специалистов по мониторингу состояния сооружений.
Список литературы
- Адамцевич Л.А., Сорокин И.В., Настычук А.В. Перспективные в условиях цифровой трансформации строительной отрасли технологии Индустрии 4.0 // Строительство и архитектура. 2022. Т. 10. № 4. С. 101-105.
- Адамцевич Л.А., Харисов И.З., Камаева Ю.В. Международный опыт применения технологий Индустрии 4.0 для мониторинга актуального состояния строительного производства // Строительное производство. 2022. № 3. С. 58-66.
- Адамцевич Л.А., Харисов И.З. Обзор технологий Индустрии 4.0 для разработки системы дистанционного управления строительной площадкой // Строительство и архитектура. 2021. Т. 9. № 4. С. 91-95.
- Гинзбург А.В., Адамцевич Л.А., Адамцевич А.О. Строительная отрасль и концепция «Индустрия 4.0»: обзор // Вестник МГСУ. 2021. Т. 16. № 7. С. 885-911.
- Адамцевич Л.А., Гинзбург Е.А., Шилов Л.А. Строительство 4.0 // Жилищное строительство. 2023. № 11. С. 18-23.
- Камаева Ю.В., Адамцевич Л.А. Перспективы использования предиктивной аналитики в строительстве // Строительство и архитектура. 2023. Т. 11. № 2. С. 12.
- Черников А.Д., Еремин Н.А., Столяров В.Е., Сбоев А.Г., Семенова-Чащина О.К., Фицнер Л.К. Применение методов искусственного интеллекта для выявления и прогнозирования осложнений при строительстве нефтяных и газовых скважин: проблемы и основные направления решения // Георесурсы. 2020. Т. 22. № 3. С. 87-96.
- Еремин Н.А., Черников А.Д., Сарданашвили О.Н., Столяров В.Е., Архипов А.И. Цифровые технологии строительства скважин. Создание высокопроизводительной автоматизированной системы предотвращения осложнений и аварийных ситуаций в процессе строительства нефтяных и газовых скважин // Neftegaz.RU. 2020. № 4 (100). С. 38-50.
- Дмитриевский А.Н., Еремин Н.А., Ложников П.С., Клиновенко С.А., Столяров В.Е., Иниватов Д.П. Анализ рисков при использовании технологий искусственного интеллекта в нефтегазодобывающем комплексе // Автоматизация, телемеханизация и связь в нефтяной промышленности. 2021. № 7 (576). С. 17-27.
- Кирнос В.П., Коковкина В.А. Разработка системы одновременной локализации и картографии на базе нейтронных сетей // Цифровая обработка сигналов и ее применение. DSPA–2023. Доклады XXV Международной конференции. Москва, 2023. С. 363-366.

